

私たちは、がんゲノムに関するデータをスーパーコンピュータにより解析し、がんのシステム異常を見出し、そこから薬効や副作用を予測し新しい治療法や予防法に繋げることを目標に研究を行っています。遺伝子は、その産物であるタンパク質のリン酸化やタンパク質間相互作用、他の遺伝子への発現制御等によって複雑な情報伝達ネットワークを形成しています。このシステムにより、必要なタンパク質が生成され私たちの生命は保たれています。一方、がんは、ゲノムに生じたさまざまな後天的変異が蓄積することで発症する病気であると言われます。生じた変異により、ある遺伝子からは異常タンパクが生成され、働かなくなることもあれば、活性が異常に高くなったり、時には、新たな機能を獲得したりすることもあります。この遺伝子の「故障」は、先程の遺伝子のネットワークに影響を与え、システムが制御不能の状況に陥った状況が「がん」であると考えることが出来るでしょう。
次世代シークエンサーというブレイクスルーにより、全DNA配列を決定する費用は、ムーアの法則を上回るスピードで下がり続け、今では1000ドルとなりました。また、この技術は、それぞれの遺伝子が生成しているメッセンジャーRNAの量も計測できるものです。個人のゲノム情報・ゲノム関連情報が手軽に手に入る時代が来たのです。しかしながら、ヒトのゲノム情報やRNAの情報は膨大です。全ゲノムのデータは、今の計測機器だと200GB程度の容量となります。そのため、データ解析には、スーパーコンピュータの計算能力が必要不可欠となります。
一言に「がん」といっても、がん細胞のゲノムの変異はさまざまです。それは、個々人でも異なりますし、同一患者のがん組織でも、ゲノムの壊れ方の異なるがん細胞集団が複数存在します。また、どの変異が高悪性度か、薬剤耐性であるとかいう「がんの特徴」を決定しているかということは、今まさに研究が進んでいるような状況です。
私たちは、NetworkProfiler という新しいデータ解析技術を統計学の理論を用いて確立しました。この方法は、がん細胞の薬剤耐性などの特徴を決定している遺伝子ネットワークの違いをそれぞれの遺伝子の生成するRNA量を計測したデータ(RNA発現データ)から発見することが出来ます。この技術を用いて、約100種類の抗がん剤それぞれの効果に関連する遺伝子ネットワークを600以上のがん細胞株のデータを用いて抽出しました。この計算は、スーパーコンピュータ「京」を用いて初めて可能となったものです。現在は、この遺伝子ネットワークの情報を次世代シークエンサーからの膨大なゲノム変異のデータと合わせて統合的な解析を進め、個々の細胞に対する抗がん剤の効き目をより精度高く予測することのできるデータ解析技術を開発しているところです。この解析の結果は、ゲノム情報に基づく個別化医療へと繋がっていきます。
がんゲノムビッグデータの
スーパーコンピュータ解析から
生命科学・医療へ
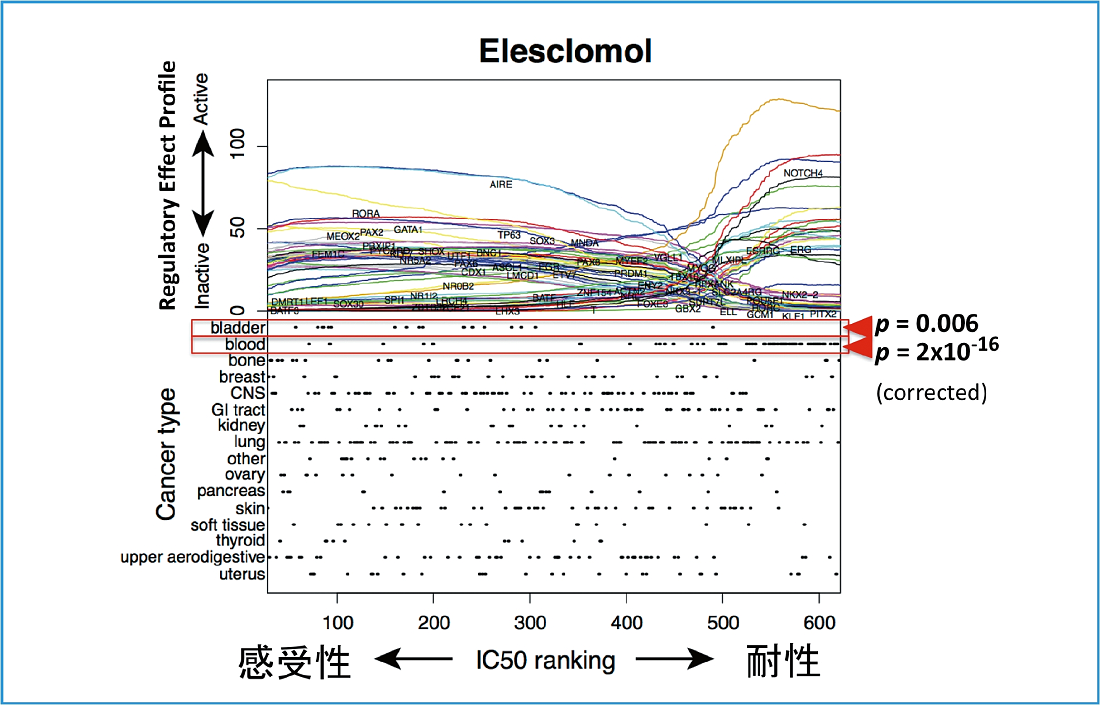
図 : 抗がん剤Elesclomolに対する感受性(横軸)と転写因子活性予測値(上パネル縦軸)。
例えば AIRE は、Elesclomol に対して感受性の高いがん細胞株では強く被制御遺伝子をコントロールしているが、耐性がん細胞株においては影響度が小さいということがわかる。
下のパネルはがん種による偏り。bladder は若干感受性に偏り、blood は耐性に偏っているが他のがん種では有意な偏りは見られない。がん種を超えたElesclomol 耐性感受性の機構が表れていることが期待される。
![]()
ZOOM IN 課題1 実験で見えない分子の形を計算で見る -ヒストンテールの構造探索-
ZOOM IN 課題3 パーキンソン病の症状再現に向けた神経系 -筋骨格系の統合シミュレーション

 |
 |
 |
 |
 |
|---|











