
 HPCI戦略プログラム 分野1 予測する生命科学・医療および創薬基盤
HPCI戦略プログラム 分野1 予測する生命科学・医療および創薬基盤
課題2 創薬応用シミュレーション
日本の優れたコンピュータ技術を活かして
革新的な分子動力学創薬に挑戦

東京大学 先端科学技術研究センター 特任教授
藤谷 秀章
(課題2 代表)
●実際に薬を創り出すことをめざす
「京」の登場によるコンピュータ能力の向上は、病気標的タンパク質に薬分子が作用し、結合するまでの分子動力学計算を可能にしました。これにより、タンパク質の形状変化を原子レベルで明らかにして薬設計を行うIT創薬革命が始まろうとしています。
私たちが取り組んでいるHPCI戦略プログラム戦略分野1の課題2「創薬応用シミュレーション」では、「京」の計算能力をフルに活用して、創薬プロセスを革新する新しいComputer Aided Drug Design(CADD)技術を確立するとともに、実際に薬を創り出すことをめざしています。同じ分子シミュレーション分野でも、課題1では、より生物学的に重要な幅広い現象が扱われるのに対して、課題2では、扱う対象を創薬がターゲットにしている病気標的タンパク質に絞り込んでいるのが特徴といえるでしょう。
これまで、国の研究機関や大学では、独自に薬を創り出した経験がありませんでした。というのも、臨床試験まで含めて薬を開発しようとすると、200億、300億といった膨大な費用がかかるからです。さらに臨床試験の前の段階で、数多くの薬候補化合物を合成する設備においても、残念ながら、多少実験できる程度しか持っていないところがほとんどです。また、抗体医薬の場合は薬といってもタンパク質であるため、基本的にはすべて大学などでも合成でき、製薬会社に頼らなくてもよいのですが、低分子化合物の場合は、考えたものを合成するというところに非常にお金がかかってしまいます。ですから、開発段階から臨床試験まで、すべて大学や研究機関だけで行って薬を創るというのは、まず不可能というのが現状です。
こうしたことから、私たちのプロジェクトでは、はじめから製薬会社とタイアップし、共同研究的なかたちで開発を進めています。実際に創薬に結び付けるためには、製薬会社を巻き込まざるを得ないわけです。国の研究費を企業のために使うようにお感じになる方がおられるかもしれませんが、実際は全く逆で、研究開発段階では、企業側が完全な持ち出しになってしまいます。それでも共同研究に参加してもらうため、こちらも製薬会社に納得してもらえるだけのシミュレーション結果を出さなければいけません。本当に薬を創り出すためには、どちらもリスクを背負いながら、真剣に取り組んでいくことになります。
●IT創薬の先駆者となることが重要
実はこの20年ほどの間、コンピュータシミュレーションによって薬を創ろうとする試みは何度も繰り返されてきましたが、未だ実現していません。その最大の理由は、タンパク質そのものを計算するだけの計算パワーが、これまでなかったからです。溶液のなかのひとつのタンパク質に、薬となる化合物が付いて機能を阻害する──こうした現象をシミュレーションするためには、少なくとも5万から10万原子、大きなものでは20万原子、さらには数百万オーダーの計算が必要になってきます。ひとつのタンパク質だけでなく、全体をシミュレーションしないと作用するかどうか分からないことも、最近明らかになってきました。そうすると、100万原子を簡単に超えてしまうのです。日本では「京」ができたことで、ようやく課題になっていた計算パワーを手に入れることができました。これまで標的タンパク質に付くか付かないか、経験的に進めてきたものが、すべてコンピュータによる計算で明らかになり、論理的に薬を開発する環境が整ったわけです。
現在、私たちが行っているIT創薬(図1)の取り組みは、ほぼ同時進行で欧米でも始まっています。米国のデヴィット・E・ショー氏が、分子動力学専用計算機(ANTON)をつくって、メガファーマ(巨大製薬会社)とともにIT創薬を進めていることをご存じの方々も多いことでしょう。こうしたことによって、今まで半信半疑だった日本の製薬会社も、IT創薬にようやく目を向けはじめています。しかし、世界的にもまだ成功例がないために、自ら投資して取り組むという段階には至っていません。そこを私たちが開拓していこうとしているわけです。
大切なのは、世界と同じスタートラインに立つ今、先駆者として走り出すことです。製薬会社の研究者とともに、実際の創薬に向けた取り組みを通して、何を計算し、どんな結果を取って、それをどのように化合物の設計に活かすかを一緒にやっていくなかで、IT創薬の研究開発の裾野を広げていくことができるはずです。実際に薬ができることが理解されれば、恐らく5年後くらいには、「京」クラスのスパコンが大手の製薬会社に導入され、さらに研究が進むことでしょう。そうした時代を拓くことが、ある意味でこのプロジェクトの最終的なゴールでもあり、「京」にとっての重要なミッションのひとつであると考えています。
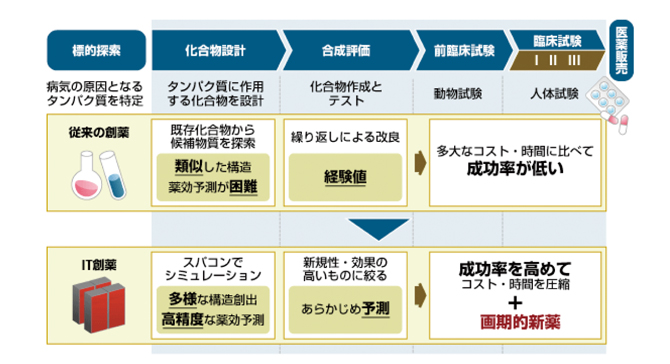
図1:従来の創薬とIT創薬の違い
図表提供/富士通株式会社
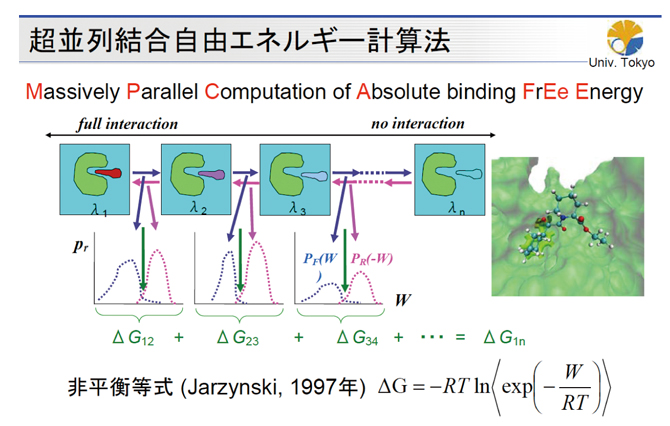
図2:超並列結合自由エネルギー計算法 MP-CAFEE法
タンパク質と化合物(薬)が溶液中で熱運動している状態において、薬の相互作用パラメータを変化させながら大量の分子動力学計算を実行し、パラメータが変化するときの仕事量分布から標的タンパク質と薬の結合自由エネルギーを求める計算法。
●「京」の高い計算能力で高精度に薬効を予測
多くの医薬品はタンパク質を標的としており、より効果的な薬を見つけ出すためには、生体内の標的タンパク質と強く相互作用する化合物(リガンド)を探し出す必要があります。私たちは、スーパーコンピュータを用いた分子動力学計算により、標的タンパク質と薬の候補である化合物を含む系のシミュレーションを行い、タンパク質と化合物間の相互作用を調べ、標的タンパク質だけに強く作用する新しい化合物を設計することにより、短時間で効率よく低分子医薬品を開発することをめざしています。
そのために私たちは、ジャルジンスキーが1997年に発見した自由エネルギー差と非平衡仕事量の関係式を用いて、結合自由エネルギーを計算するアルゴリズムであるMP-CAFEE法を考案しました(図2)。これは、化合物の他分子に対する相互作用が存在する状態から、相互作用が全く消滅して離れる仮想状態までの複数の中間状態に関して分子動力学計算を実行し、隣の状態に移行するために必要な仕事量から結合自由エネルギーを求めるものです。これにより、溶液中の標的タンパク質と化合物の結合自由エネルギーを正確に計算することができます。MP-CAFEE法の特徴は、原子レベルから計算しているため、タンパク質のキャラクターに影響されず、あらゆるタンパク質に対して安定的に高い精度が出せる点です。その分大きな計算パワーが必要で、2005年に発表した時点では、そのような膨大な計算をいったいどの計算機でやるつもりなのかといわれていました。しかし、「京」ができたことにより、具体的な成果を出すための条件が整ったわけです。
2011年5月より、超並列結合自由エネルギー計算プログラムMP-CAFEEを「京」に移植する作業を開始し、これまでにMP-CAFEEが、「京」で正常に動作していることが確認できています。現在は、より高速に計算するための調整を行いつつ、8月からは、「京」向けに改造したMP-CAFEEを用いて、ターゲットとしている癌や白血病などの標的タンパク質に対する薬を実際に開発するための計算が始まっています。そのためには、数百万単位のさまざまな化合物のなかから、うまく作用しそうな候補化合物を、その構造を見ながら探し出す必要があります。そこで、コンピュータを使った薬設計ビジネスを進めている富士通株式会社バイオIT事業本部との共同研究などによって、まずはMP-CAFEE計算に持ち込むおよそ100のオーダーの候補化合物の選別が行われました。候補化合物は、既存の化合物だけでなく、より効果的に作用する新規化合物も設計されています。もちろんその際には、合成が可能かどうか、毒性(副作用)がないかどうかのチェックも行われます。IT創薬のメリットは、コストや時間を圧縮できるということもありますが、何よりも大きいのは、既存の化合物にとらわれることなく、分子シミュレーションによって多様で新しい化合物を設計したり、候補化合物を予測したりできる点にあります。
今年度は、比較的小さな標的タンパク質に対して薬候補化合物がひとつのシリーズとして出せるのではないかと考えています。計算機時間の関係で、まずはいちばん確実なものを最優先に進め、あとは今後より大きなもの、難しいものを扱うための準備ということになると思います。実質的にはあと3年ですから、それまでに今年度出た成果をはじめ、臨床試験まで行く可能性のあるものを複数個創るというのが、最大の目標です。
先に申し上げた通り、日本の製薬会社にこれまでなかなか成果が出なかったIT創薬に目を向けてもらい、一緒に取り組んでもらうということが、このプロジェクトのひとつの目的でもあるわけですが、世界の動向や「京」の完成ということも手伝って、製薬会社の反応は非常によく、オファーも数多く来ています。国のプロジェクトですから、こちらもできるだけ多くの製薬会社に声をかけて、コラボレーションの話をさせてもらっていますが、すでに多くの会社からいろいろなご提案をいただき、「できれば今年度から始めたい」という声も出ています。もちろんすぐに始められるわけではないので、今はディスカッションを続けながら今後に向けて準備をしているところです。
BioSupercomputing Newsletter Vol.7
- SPECIAL INTERVIEW
- 「京」開発担当者に聞く今後のスパコン戦略とエクサスケールに向けた取り組み
富士通株式会社 テクニカルコンピューティングソリューション事業本部
エグゼクティブ・アーキテクト 奥田 基 - 「京」への展開で、実利用に向けた最適化とさらなる規模の拡張を進める大規模仮想ライブラリ
東京大学大学院工学系研究科 化学システム工学専攻 教授 船津 公人
- 研究報告
- 水の誘電率計算から得られる古くて新しい問題
大阪大学蛋白質研究所 中村 春木(分子スケールWG) - 大規模並列計算用流体・構造連成解析プログラムの開発
理化学研究所 情報基盤センター 杉山 和靖(臓器全身スケールWG) - スーパーコンピュータを用いた大規模遺伝子ネットワーク推定ソフトウェア SiGN
東京大学大学院情報理工学系研究科 玉田 嘉紀(データ解析融合WG) - ISLiM研究開発ソフトウェアのソース・コード公開に向けた活動
理化学研究所 次世代計算科学研究開発プログラム 田村 栄悦
- SPECIAL INTERVIEW
- 「京」を用いた大規模シミュレーションによって細胞内分子ダイナミクスの理解と予測を実現する
理化学研究所 基幹研究所 杉田理論分子科学研究室 主任研究員 杉田 有治(課題1 代表) - 日本の優れたコンピュータ技術を活かして革新的な分子動力学創薬に挑戦
東京大学 先端科学技術研究センター 特任教授 藤谷 秀章(課題2 代表)
- 報告
- 大学の新入生に行った計算生命科学の講義
理化学研究所 HPCI計算生命科学推進プログラム 鎌田 知佐
- 体制
- 計算科学技術推進体制