

「京」に続くスパコン環境および技術開発の動向を探る
「京」開発担当者に聞く今後のスパコン戦略と
エクサスケールに向けた取り組み

富士通株式会社
テクニカルコンピューティングソリューション事業本部 エグゼクティブ・アーキテクト
奥田 基
●2015年ころには「京」クラスがオンサイトで利用可能に!?
━ 「京」の供用が開始されましたが、利用はプロポーザル制で誰もが自由に使える状況ではありません。10PFLOPSという計算性能を有するスパコンが、日本に「京」しかないので、プロポーザル制で行なわざるを得ないのですが、多くの研究者は自分が使いたいときに使える高度なスパコン環境を望んでいると思います。「京」の商用版である「FX10」の国内外での導入も進んでいるようですが、10ペタクラス導入の話は聞いていません。こうした状況のなか、研究者が10ペタクラスを自由に使える日はいつごろになるのか、また「京」を越えるスパコンの開発はどのように進められていくのか、課題はどこにあるのかなど、今後の動向についてお話をうかがわせてください。
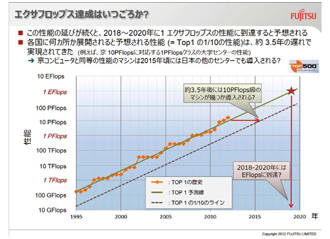
奥田 これまでの世界のスパコン性能競争(TOP500第1位)の歴史を見ると、10年間で約1,000倍の性能向上がなされてきました。このペースで線を延ばしていくと、だいたい2018 ~ 20年ころに1EFLOPS(エクサフロップス)のマシンができるであろうと予測されており、日本もそれをめざしています。一方で、研究者が自由に使えるスパコンについて考えてみると、そのスパコンは各国に何台も導入されている必要があり、その性能はTOP性能のスパコンの1/10程度と考えられます。 実際に、日本でも「京」の完成とほぼ同時に、東京大学情報基盤センターに「京」の約1/10のピーク性能1.13PFLOPSの新スパコンシステム(Oakleaf-FX)が導入されています。 約3.3年で10倍の性能向上が見られますから、約3.3年経つと、現在のTOP500第1位と同等の性能を持つスパコンが各国に何カ所か展開されると予想されます。すなわち、「京」と同等の性能を持つスパコンが大学や研究機関に入るようになるのは、2015年くらいではないかと予測されます。
━ 逆にいうと、10ペタクラスのスパコンが何台か大学などに入る2015年くらいには、日本で100ペタクラスのスパコンが開発されるということですか。
奥田 ベンダー各社、それぞれ考え方や取り組みは異なりますが、私たち富士通がどんなことを考えているかというと、これまで「京」の開発を進めてきたことから、今後も国のプロジェクトに沿いながら、さまざまな製品の開発を進めていくという方向性を打ち出しています。これから本格的な運用が始まる「京」に対しても、運用支援や利用支援、アプリ最適化支援を行っていくと同時に、これから研究者のみなさんが「京」向けのアプリケーションをどんどん開発され、チューニングし最適化していくなかで蓄積されるソフトウェアの資産を、さらに発展させながら利用できる環境を継続的に提供していくことが、これからの私たちの役割であると思っています。商用機である「FX10」の提供もまさにそうですが、さらに2014 ~ 15年ころの製品化をめざして、エクサスケールへの繋ぎという意味で「Trans-Exa」と呼んでいますが、「100PFLOPS級Trans-Exaシステム」を開発中です。これは、「京」や「FX10」のアプリケーションを、そのまま実行することができることを念頭に置いたマシンです。アーキテクチャも同様のコンセプトで、プログラミングモデルを変える必要もありません。もちろん、コンパイルし直してもらえれば、より高い性能を出すことができます。「FX10」は一つのCPUの性能が「京」の1.85倍(ピーク性能)上がっており、他にも運用性を向上できる機能が備わっていますが、「Trans-Exa」では、CPU性能、ネットワーク性能、さらには実装密度、消費電力も大幅に改善したマシンを予定しています。もちろん100ペタまで拡張できるとはいえ、100ペタをそのまま導入できるところは限られるでしょうが、それでも、数ペタクラスのスパコンがオンサイトで利用できる環境が、2015年ころには大学や研究機関に整うことになるはずです。
●エクサスケール実現への道のり
━ スパコン開発における今後の技術動向については、どのようにお考えですか。
奥田 今年のTOP500で、非常に大きな技術的なジャンプがありました。それは第1位になった米国「Sequoia」の電力効率(電力あたりの性能)です。これまでのTOP1マシンのなかでは、「京」はいちばんよかったのですが、「Sequoia」は2,000GFLOPS/KW以上という圧倒的な差をつけて成績を塗り替えました。要するに、これまでにない非常に低消費電力のスパコンが誕生したということです。一方、CPUのなかにはコアと呼ばれる演算ユニットがありますが、TOP1マシンの1つのコアあたりの性能(LINPACK性能)は、この5年ほどの間、それほど大きく変わっていません。「京」は比較的高く、約15GFLOPSですが、「Sequoia」では逆に下がって、10GFLOPS程度です。つまり、現在はコアの性能を高めるというより、コアの数を増やすことによって性能を向上させる方向に動いているということです。
━ 消費電力を下げる、コアの数を増やす、この2点がトレンドということですね。いい換えれば、それが今後のエクサスケールに向けた課題でもあるのでしょうか。
奥田 そうですね。先ほど「Trans-Exa」の話をしましたが、私たちは、これをエクサスケール実現に向けた技術開発の第1段階と位置付けて、さらに第2段階の研究開発を経てエクサスケールシステムを実現させたいと考えています。第1段階、つまり現在開発中の「Trans-Exa」では、1つのコアの性能を高めるとともに、さらなるマルチコア化を進めようとしています。「京」は8コアで、「FX10」は16コアですが、次はさらにコア数を増やしたい考えです。CPUの性能を高めることに伴い、当然ながらインターコネクトの高性能化も図ります。さらに低消費電力化も進める考えですが、実はこれがいちばん大きな課題です。それでも、「Sequoia」を越えることを目標に開発を続けているところです。あとは、実装密度、つまり面積あたりどれだけのCPUが搭載されているかということですが、これももっと高めて、高性能・高密度をめざしています。こうした第1段階を経て、さらにエクサスケールをめざすのですが、その間にはかなり大きな技術的なジャンプがあるだろうと考えています。先ほどの予測では、エクサ到達は2018 ~ 20年ですから、第1段階の開発からさらに3 ~ 5年あるわけです。コンピュータの世界で5年先のテクノロジーというのは、正直なところ、どうなるのか読めない部分があります。実際のところ、CPUの単なる演算性能の向上だけでしたら、方向性は見えていますが、低消費電力化に関しては、まだこれからという部分があります。開発中の100PFLOPS級のマシンではかなりメドがついているのですが、さらにその10倍となると、今のテクノロジーの延長では難しく、新しい技術の創出に期待しています。また、エクサスケールの実現には、さらなる高信頼化のための研究開発も必要です。
アプリケーション開発においても、どのような形にしろ、エクサシステムではさらに並列度を高めざるを得ないわけですから、プログラミングモデルも変える必要が出てくるかもしれません。エクサスケールというのはまだまだ読み切れないところがあるわけです。ですから、100PFLOPS級システムが、次のエクサスケールに進むための準備をするためのプラットフォームになるのではないかと考えています。マルチコアが進み、SIMDが導入されたマシンをどうやって使いこなすかという研究開発を進めて、次に繋げていただきたいと思っています。
 |
 |
エクサフロップス達成はいつごろか? |
エクサスケール実現に向けた課題と取り組み |
●世界に負けないスパコンの開発をめざす
━ 「Trans-Exa」とされるマシンは、技術者にとっても研究者にとっても、次のエクサスケールマシンのテスト的な位置づけになるということですね。
奥田 「京」の場合も、プロジェクトの開始と同時にアプリケーションのプロジェクトが走り出しました。2011年度からHPCI戦略プログラムが動き出しましたが、後半で100PFLOPS級のマシンを使って、次に向けた準備を始めていただければ、エクサスケールで何をすればよいのかが見えてくるのではないでしょうか。
━ かつてのように、ハードウェアが進化すれば、放っておいても計算が早くなるという時代ではありませんからね。
奥田 「コ・デザイン」といわれるように、技術者と研究者が一緒になって、マシンとアプリを設計・開発していく時代だと思っています。「京」におけるグランドチャレンジアプリケーションの開発がそうであったように、事前の準備期間がないと、エクサスケールのマシンは完成したけれど、性能が活かせるアプリがないということになりかねません。「京」の場合は、4、5年前から準備が始まっていて、いろいろな分野で、これから続々とその成果が出ようとしている段階に来ていますよね。2013、14年に優れた成果が出れば、次の研究開発への弾みになると思いますし、逆にいえば、そのときに次に進むためのマシンが、「京」のほかにも用意されているということが、とても重要なことだと思います。私たちとしても、そうした流れを描いて、100PFLOPS級マシンの開発を行っています。
━ ちょうど「京」の前に「FX1」が出て、それが「京」のアーキテクチャと似ているということで、いくつかの研究機関や大学にいち早く導入されたという経緯があったと思いますが、それと同じように、エクサスケールに向けた準備として「Trans-Exa」を活用してほしいということですね。
奥田 そのくらいの準備がないと、いくら性能の高いマシンができても、すぐには性能が出せないと思っています。
━ エクサスケール実現に向けた第2段階で、最大の課題は何でしょうか。
奥田 やはり、消費電力の低減がいちばんのポイントになると思います。CPU性能の向上に関しては、半導体テクノロジーが進んで、1つのチップのなかに演算回路を数多く入れる事は可能と考えられています。ただ、その高性能CPUの演算回路が全て動くと、消費電力がものすごいことになってしまい、効率的に動かすことができません。どうしても消費電力を下げることが課題になってきます。電力をできるだけ喰わずに演算できる回路を考えることはとてもたいへんですが、そうしたことにも取り組んでいかないといけません。とにかく未知数な部分も含めて、さまざまな技術開発の積み重ねによってエクサスケールを実現させたい、実現させなければいけないと考えています。
━ 開発者としては、より高いところをめざして進んでいく努 力を止めることはできない。
奥田 もちろん、続けていかなければいけないと思っています。「京」を使い出した研究者の方から、一度「京」を使ったらもう元には戻れませんという話を聞いています。開発が始まったころは、「10ペタなんて必要なの?」、「使えるアプリがあるの?」といった議論もあったと思いますが、5年たったら状況は全く変わっている、そういうものではないでしょうか。それに、日本の研究者が他の国の人たちと一緒にプロジェクトをやろうとするときに、自分たちが“強み”を持っていなければ、対等に議論することもできませんよね。今、世界中の人々が、「京」に関心を持ち、「京」を使ってどんな研究成果が出るのかを見守っています。ですから、今後も世界に負けないマシンをつくり続けていかなければいけないと考えています。
 |
BioSupercomputing Newsletter Vol.7
- SPECIAL INTERVIEW
- 「京」開発担当者に聞く今後のスパコン戦略とエクサスケールに向けた取り組み
富士通株式会社 テクニカルコンピューティングソリューション事業本部
エグゼクティブ・アーキテクト 奥田 基 - 「京」への展開で、実利用に向けた最適化とさらなる規模の拡張を進める大規模仮想ライブラリ
東京大学大学院工学系研究科 化学システム工学専攻 教授 船津 公人
- 研究報告
- 水の誘電率計算から得られる古くて新しい問題
大阪大学蛋白質研究所 中村 春木(分子スケールWG) - 大規模並列計算用流体・構造連成解析プログラムの開発
理化学研究所 情報基盤センター 杉山 和靖(臓器全身スケールWG) - スーパーコンピュータを用いた大規模遺伝子ネットワーク推定ソフトウェア SiGN
東京大学大学院情報理工学系研究科 玉田 嘉紀(データ解析融合WG) - ISLiM研究開発ソフトウェアのソース・コード公開に向けた活動
理化学研究所 次世代計算科学研究開発プログラム 田村 栄悦
- SPECIAL INTERVIEW
- 「京」を用いた大規模シミュレーションによって細胞内分子ダイナミクスの理解と予測を実現する
理化学研究所 基幹研究所 杉田理論分子科学研究室 主任研究員 杉田 有治(課題1 代表) - 日本の優れたコンピュータ技術を活かして革新的な分子動力学創薬に挑戦
東京大学 先端科学技術研究センター 特任教授 藤谷 秀章(課題2 代表)
- 報告
- 大学の新入生に行った計算生命科学の講義
理化学研究所 HPCI計算生命科学推進プログラム 鎌田 知佐
- 体制
- 計算科学技術推進体制