Disease appears as a phenomenon of disorders in related organs. As a background of disease, we need to consider our genome, which is often called “the blueprint of life”, and various data of molecules such as epigenome, RNA, protein, etc. These are collectively-referred to as “omics” and drive cells for creating biological functions. Further, each cell in our individual has a specific state of cell called “cellular context” that changes with the environmental factors and aging. Cellular contexts vary from cells to cells, and therefore, the functions of organs also depend on their cellular contexts. Moreover, for the genome, which was previously considered not to change through our life, it has been recently reported that genomic mutations accumulate along with aging steadily in our hematopoietic stem cells. Cancer develops in the long organism-spatiotemporal process while being affected by various environmental factors. It is no exaggeration to say that this process begins since a person is born. Not only the variations in population but also everybody has a variety in its life. It may be said that this is the biological reality of the aging society that genomic science has unraveled.
On the other hand, the genome sequencing technologies, which can also produce epigenomic data and RNA sequence data, have already produced genome sequence data in petabyte order. Moreover, high precision clinical data such as imaging or physiological data have also made a large-scale data mountain. In the Grand Challenge Program and the following Strategic Programs for Innovative Research Field 1, the world’s top level simulation technologies had been developed that include the heart simulator UT-Heart that successfully used the full power of the K computer. We had also development of technologies for large-scale analysis of life data that allowed us to analyze all genes and non-coding RNAs of size more than dozens of terabytes. These technologies led us to important discoveries in cancer biology and development of various prediction methods (e.g. for drug resistance, cancer survival) that could not be achieved without the K computer.

Of course, it was a very epoch-making scientific contribution that the multi-scale simulator UT-Heart achieved a full simulation of 1.5 heartbeats from sarcomere to blood ejection. It should be emphasized that this simulation took 17 hours by continuously employing almost all nodes of the K computer just for 1.5 heartbeats. In cancer research, international collaborations are building a catalog of cancer mutations with frequency more than 5% for major 50 cancer types/subtypes. The world-wide total computing power spent for this catalog building was similar to the power of the K computer. However, in order to understand “personal cancer”, we need to carry out the comprehensive analysis of mutations with frequency less than 1% by whole genome sequencing. This analysis requires, theoretically, 5,000 days by the K computer, an unrealistic analysis. As described above, while human diversity has been identified from various viewpoints, a strong need is to develop technologies to fill the gap between the molecular mechanisms of individual pathologies and the large-scale imaging and physiological data, and further, health and genome information. The above heart simulation and cancer genome research are some of the extremely important scientific/ biomedical issues that Japan and humans must challenge. However, even for these cases alone, we need a new computing environment exceeding the K computer, and simultaneously we will face with a big mission that we develop technologies to fully exploit it for overcoming the difficulties. It has been gradually recognized that the complexity of integrative understanding of diseases is far beyond human abilities. This is one of the reasons why development of the post-K computer is inevitable.
In priority issue 2, our goal is to establish the integrated computational life science that constitutes the basis for personalized/preventive medicine. This requires a methodology for comprehensive understanding of pathological states and exploration of their effective treatments through a view from genome to the whole body, both environment- and organism-spatiotemporally. We consider that this methodology can be realized by "information technology", "application of physics principles", and "utilization of big data" enhanced with the post-K scale computation.
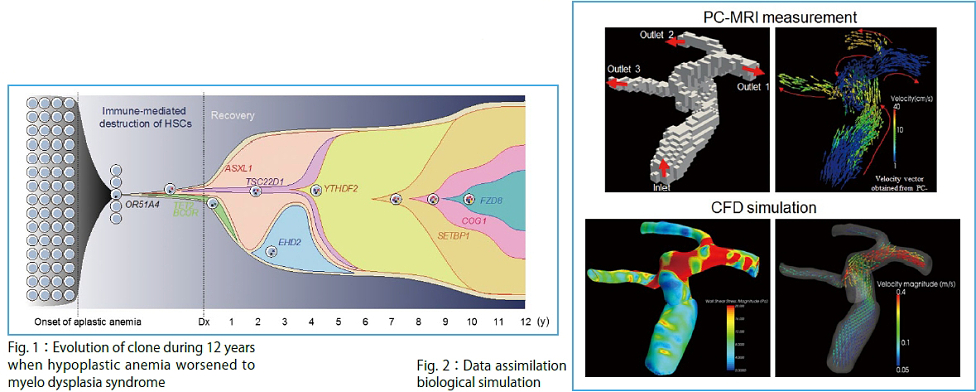
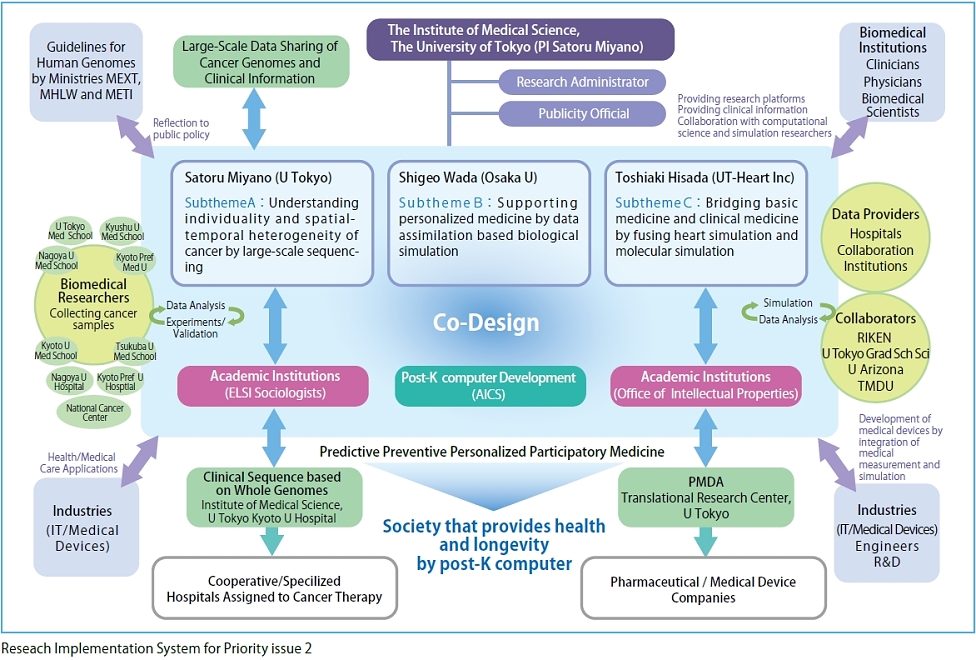
To achieve the goal, we are tackling three subthemes. In Subtheme A, "Understanding individuality and spatial-temporal heterogeneity of cancer by large-scale sequencing" (Supervisor: Satoru Miyano) (Fig.1), we will analyze large-scale data of an unprecedented scale in the field of life sciences. In Subtheme B, "Supporting personalized medicine by data assimilation based biological simulation" (Supervisor: Shigeo Wada (Graduate School of Engineering Science, Osaka University) (Fig. 2), we are developing a technique to assimilate individual data for a high-level, organism hierarchy integrative simulation. Parallel to the approach based on the large-scale data, in Subtheme C, "Bridging basic medicine and clinical medicine by fusing heart simulation and molecular simulation" (Supervisor: Toshiaki Hisada (UT-Heart Inc) (Fig. 3), we are integrating studies on the molecular cellular level and those on individual organ levels to develop a simulation model for quantitative capture by associating micro with macromechanics.
In the present era when we will witness the advent of the super-aged society, we believe that the solutions by the priority issue 2 will constitute an essential basis to support the healthy and longevity society. Further, for various diseases that occur along with aging, we believe that contributions of the new paradigm, "Integrated Computational Life Science", to the health of citizens should be of great social significance.
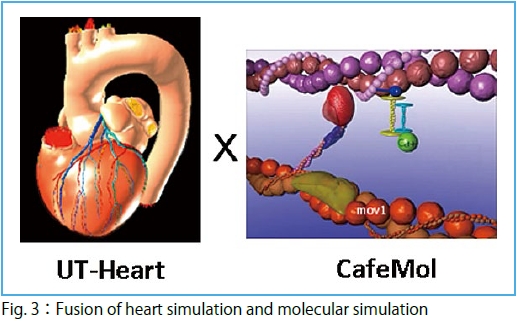
![]()
Innovative drug discovery infrastructure through functional control of biomolecular systems

 |
 |
 |
 |
 |
 |
|---|










